











就连陆奇都说他跟不上大模型时代的狂飙速度了。他让下属做“大模型日报”,一方面便于他跟上论文和信息更新,另一方面给奇绩生态创业者共享。他用了三个“实在”表达这一点。“我实在不行了,论文实在是跟不上,代码实在是跟不上。Just too much(太多了)。”陆奇在近期一次分享活动上说。
这样的时刻还从没有过。奇绩创坛创始人兼CEO陆奇是中国AI布道人,也是中国针对大模型最有发言权的人之一。他曾在全球巨头身居要职,先后任职于IBM、雅虎、微软、百度,曾是华人在美国科技公司最有权威的高层人士,位至雅虎和微软执行副总裁,回国加盟百度出任集团总裁兼COO。陆奇以勤勉的工作为科技圈著称——每天清晨4点起床,跑步5英里,6点准时到办公室。
同时,他和OpenAI有着深厚渊源。陆奇所掌管的奇绩前身是YC中国,是美国著名创业孵化器YC(Y Combinator)的中国分支。他也是YC全球研究院院长。而OpenAI首席执行官Sam Altman正是YC二代接班者、现任总裁。两人虽相差24岁,却是忘年交,相识已逾18年。当初正是Sam Altman屡次力邀陆奇加盟YC。所以,陆奇对YC、对Sam Altman和OpenAI都有长期的近距离观察。
2023年4月22日,陆奇在上海举行小规模演讲,腾讯新闻有幸参与了旁听。陆奇希望帮助中国创业者认清这次历史性的拐点时刻,定位今天的时代坐标、找准自己的位置。“这个时代跟淘金时代很像,”他说道,“如果你那个时候去加州淘金,一大堆人会死掉。但是卖勺子、卖铲子的人永远可以赚钱。”
陆奇很反感蹭热点,他一再警示创业者蹭热点只会浪费机会。到现在为止,你几乎很难在公开渠道听到陆奇的观点。这也让本次演讲具有稀缺性。
事实上,在大模型快速达成社会共识之际,一部分人期待陆奇博士披甲上阵,做“中国的Sam Altman”——扮演可能比一名投资者、布道者更关键的角色。但据奇绩内部人说:“Qi目前100%时间花在奇绩。”
腾讯新闻作者将这场分享进行了完整的整理——演讲涵盖他对大模型时代的宏观思考,包括拐点的内在动因、技术演进、创业公司结构性机会点以及给创业者的建议。大家可以各取所需。
好了,让我们来看看陆奇怎么说。为了方便阅读,作者做了一些字句修改和文本优化。
01
社会性拐点的核心
是一项大型成本从边际变成固定
我们俩是忘年交。他是一个很善良也很奇怪的小孩,今天很高兴他能这样改变世界。前不久,我春节在美国3个月,也到OpenAI和Sam聊了一些。
首先,怎么理解这个新范式?这张图能把ChatGPT和OpenAI所带来的一切讲清楚。之后,基于第一性原理,你自然会推演出所在赛道的机会和挑战。
这张图是“三位一体结构演化模式”,本质是讲任何复杂体系,包括一个人、一家公司、一个社会,甚至数字化本身的数字化体系,都是复杂体系。“三位一体”包括:
-
“信息”系统(subsystem of information),从环境当中获得信息;
-
“模型”系统(subsystem of model),对信息做一种表达,进行推理和规划;
-
“行动”系统(subsystem of action),我们最终和环境做交互,达到人类想达到的目的。
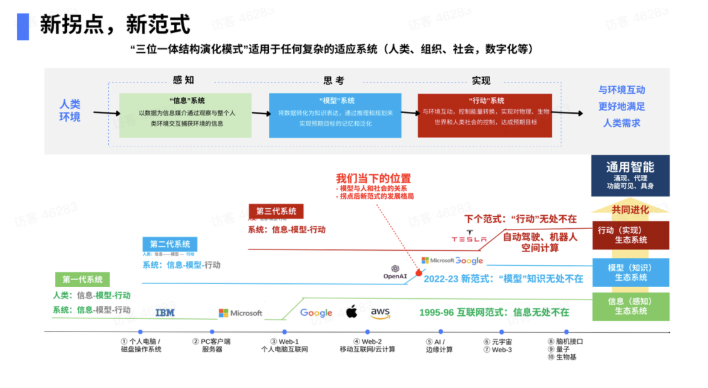
任何体系,都是这三个体系的组合,数字化系统尤其如此。数字化和人分不开。人也一样,人要获得信息、表达信息、行动解决问题或满足需求。
基于此,我们可以得出一个简单结论。今天大部分数字化产品和公司,包括Google、微软、阿里、字节,本质是信息搬运公司。一定要记住,我们所做的一切,一切的一切,包括在座的大部分企业都在搬运信息。Nothing more than that,You just move bytes(仅此而已,你只是移动字节)。但它已经足够好,改变了世界。
早在1995-1996年,通过PC互联网迎来一个拐点。那时我刚从CMU(卡内基梅隆大学)毕业。大量公司层出不穷,其中诞生了一家伟大公司叫Google。为什么会有这个拐点?为什么会有爆炸式增长?把这个观点讲清楚,就能把今天的拐点讲清楚。
原因是,获取信息的边际成本开始变成固定成本。
一定要记住,任何改变社会、改变产业的,永远是结构性改变。这个结构性改变往往是一类大型成本,从边际成本变成固定成本。
举个例子,我在CMU念书开车离开匹茨堡出去,一张地图3美元,获取信息很贵。今天我要地图,还是有价钱,但都变成固定价格。Google平均一年付10亿美元做一张地图,但每个用户要获得地图的信息,基本上代价是0。也就是说,获取信息成本变0的时候,它一定改变了所有产业。这就是过去20年发生的,今天基本是free information everywhere(免费的信息无处不在)。
Google为什么伟大?它把边际成本变成固定成本。Google固定成本很高,但它有个简单商业模式叫广告,它是世界上高盈利、改变世界的公司,这是拐点关键。
今天2022-2023年的拐点是什么?它不可阻挡、势不可挡,原因是什么?一模一样。模型的成本从边际走向固定,因为有件事叫大模型。
模型的成本开始从边际走向固定,大模型是技术核心、产业化基础。OpenAI搭好了,发展速度爬升会很快。为什么模型这么重要、这个拐点这么重要,因为模型和人有内在关系。我们每个人都是模型的组合。人有三种模型:
-
认知模型,我们能看、能听、能思考、能规划;
-
任务模型,我们能爬楼梯、搬椅子剥鸡蛋;
-
领域模型,我们有些人是医生,有些人是律师,有些人是码农。
That’s all。我们对社会所有贡献都是这三种模型的组合。每个人不是靠手和腿的力量赚钱,而是靠脑袋活。
简单想一想,如果你没有多大见解,你的模型能力大模型都有,或者大模型会逐步学会你所有的模型,那会怎样?——未来,唯一有价值的是你有多大见解。
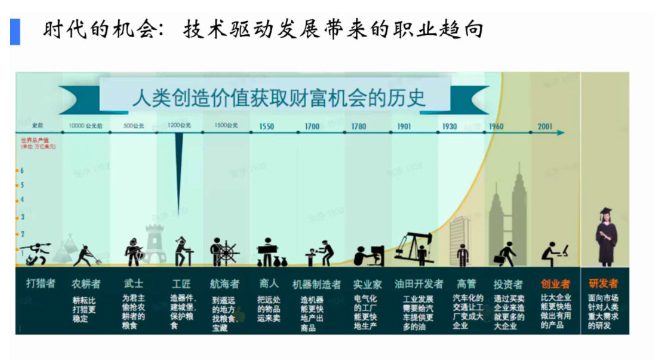
人类社会是技术驱动。从农业时代,人用工具做简单劳动,最大问题是人和土地绑定,人缺少流通性,没有自由。工业发展对人最大变化是人可以动了,可以到城市和工厂。早期工业体系以体力劳动为主、脑力劳动为辅,但随着机械化、电气化、电子化,人的体力劳动下降。信息化时代以后,人以脑力劳动为主,经济从商品经济转向服务经济——码农、设计师、分析师成为我们时代的典型职业。

这一次大模型拐点会让所有服务经济中的人、蓝领基本都受影响,因为他们是模型,除非有独到见解,否则你今天所从事的服务大模型都有。下一时代典型的职业,我们认为是创业者和科学家。
所以,这次变革影响每个人。它影响整个社会。
02
我所看到的三个拐点
下个拐点是什么?
下个拐点将是组合:“行动”无处不在(自动驾驶、机器人、空间计算)。也就是人需要在物理空间里行动,它的代价也从边际走向固定。20年后,这个房子里所有一切都有机械臂,都有自动化的东西。我需要的任何东西,按个按钮,软件可以动,今天还需要找人。
那么,哪些公司能走到下个拐点、站住下个拐点?我认为特斯拉有很高概率,它的自动驾驶、机器人现在很厉害。微软今天跟着OpenAI爬坡,但怎么站住下个拐点?
接下来讲一下我们看到的三个拐点:
① 今天信息已经无处不在了,接下来15-20年,模型就是知识,将无处不在。以后手机上打开,任何联网,模型就过来了。它教你怎么去解答法律问题,怎么去做医学检验。不管什么样的模型都可以无处不在。
② 在未来,自动化、自主化的动作可以无处不在。
③ 人和数字化的技术共同进化。Sam最近经常讲,它必须要共同进化,才能达到通用智能(AGI)。通用智能四大要素是:涌现(emergence)+代理(agency)+功能可见性(affordence)+具象(embodiment)。
总结来说,我们从根本性的三位一体结构分析未来,从过去的历史拐点能清晰看到今天所面临的拐点,本质是模型成本从边际走向固定,将有一家甚至多家伟大公司诞生。毫无疑问,OpenAI处于领先。
虽然讲得有点早,但我个人认为,OpenAI未来肯定比Google大。只不过是大1倍、5倍还是10倍。
03
OpenAI核心就坚信两件事
发展速度连Sam本人都惊讶
下面我从技术角度讲OpenAI大事迹,它怎么把大模型时代带来的?
为什么讲OpenAI,不讲Google、微软。讲真心话,因为我知道,微软好几千人也做这个,但不如OpenAI。一开始比尔·盖茨根本不相信OpenAI,大概6个月前他还不相信。4个月前看到GPT-4的demo(产品原型),目瞪口呆。他写了文章说:It’s a shock,this thing is amazing(这太令人震惊了,这东西太神奇了)。谷歌内部也目瞪口呆。
OpenAI一路走下来的关键技术:
-
GPT-1是第一次使用预训练方法来实现高效语言理解的训练;
-
GPT-2主要采用了迁移学习技术,能在多种任务中高效应用预训练信息,并进一步提高语言理解能力;
-
DALL·E是走到另外一个模态;
-
GPT-3主要注重泛化能力,few-shot(小样本)的泛化;
-
GPT-3.5 instruction following(指令遵循)和tuning(微调)是最大突破;
-
GPT-4 已经开始实现工程化。
-
2023年3月的Plugin是生态化。
OpenAI的融资结构为什么这么设计?和Sam早期目标和对未来的判断分不开。他知道要融很多钱,但股权设计有一个很大挑战——容易把回报和控制混在一起——所以他要设计一个结构,让它不受任何股东的制约。于是,OpenAI的投资者没有控制权,他们的协议是一种债的结构。如果赚完2万亿,接下来是non-profit(不再盈利了),一切回归社会。这个时代需要新的结构。

它势不可挡。Sam Altman自己都surprise,连他都没想到会那么快。
如果大家对技术感兴趣,Ilya Sutskever(OpenAI联合创始人兼首席科学家)很重要,他坚信两件事。
第一是模型架构。它要足够深,只要到了一定深度,bigness is betterness(大就是好)。只要有算力,只要有数据,越大越好。他们一开始是LSTM(long short term memory),后来看到Transformer就用Transformer。
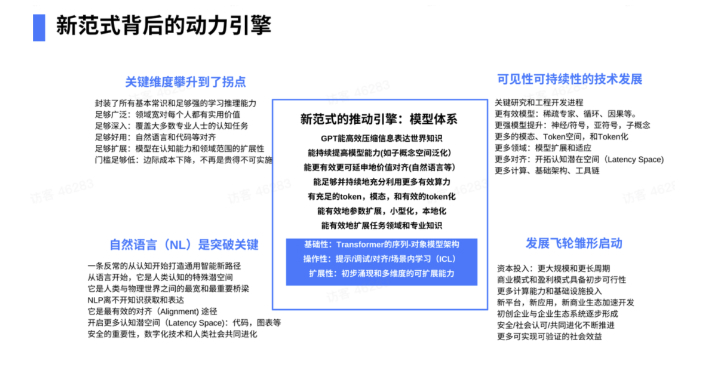
第二个OpenAI相信的是,任何范式、改变一切的范式永远有个引擎,这个引擎能不断前进、不断产生价值。
这个引擎基本是一个模型体系(model system),它的核心是模型架构Transformer,就是sequence model(序列模型):sequence in、sequence out、encode、decode后者decode only。但最终的核心是GPT,也就是预训练之后的Transformer,它可以把信息高度压缩。Ilya有个信念:如果你能高效压缩信息,你一定已经得到知识,不然你没法压缩信息。所以,你把信息高效压缩的话,you got to have some knowledge(你得有一些知识)。
Ilya坚信GPT3、3. 5,当然GPT-4更是,它已经有一个世界模型在里面。虽然你做的事是predict next word(预测下一个关键词),这只不过是优化手段,它已经表达了世界的信息,而且它能持续地提高模型能力,尤其是目前研究比较多的在子概念空间当中做泛化。知识图谱真的不行。如果哪个同学做知识图谱,我认真跟你讲,你不要用知识图谱。我自己也做知识图谱20多年,just don’t do that。Just pretty bad。It does not work at all。You should use Transformer。(不要那样做。很糟糕。它根本不起作用。你应该使用Transformer。)
更重要的是用增强学习,加上人的反馈,与人的价值对齐。因为GPT已经做了4年多,知识已经封装在里面了,过去真的是用不起来,也很难用。
最大的是对齐(alignment engineering),尤其是instruction following和自然语言对齐。当然也可以跟代码、表格、图表对齐。
做大模型是很难的,很大难度是infra(基础设施)。我在微软的时候,我们每个服务器都不用网卡,都放了FPGA。网络的IO的带宽速度都是无限带宽技术(Infiniband),服务器和服务器之间是直接访问内存。为什么?因为Transformer是密度模型,它不光是算力问题,对带宽要求极高,你就想GPT-4需要24000张到25000张卡训练,试想世界上多少人能做这种系统。所有数据、data center网络架构都不一样。它不是一个三层的架构,必须是东西向的网络架构。所以这里要做大量的工作。
Token很重要。全世界可能有40-50个确定的token,就是语言的token和模态,现在有更多的token化。当然现在更多的模型的参数小型化、本地化,任务领域的专业知识可以融入这些大模型当中。它的可操纵性主要是靠提示和调试,尤其是根据指令来调,或者对齐来调试,或者in-context learning(上下文学习),这个已经贯彻比较清晰了。它的可操作性是越来越强。可拓展性基本上也足够。
加在一起,这个引擎并不完美。足够好、足够强的引擎,我没从没有过。
以上是引擎,拐点是怎么到的?ChatGPT能在历史上第一次两个月1亿活跃用户,挡都挡不住,为什么?
① 它封装了世界上所有知识。
② 它有足够强的学习和推理能力,GPT-3能力在高中生和大学生之间,GPT-4不光是进斯坦福,而且是斯坦福排名很靠前的人。
③ 它的领域足够宽,知识足够深,又足够好用。自然语言最大的突破是好用。扩展性也足够好。当然还是很贵,像2万多张卡,训练几个月这么大的工程。不过也没贵到那么离谱——Google可以做,微软可以做,中国几个大公司能做,创业公司融钱也能做。
加在一起,范式的临界点到了。拐点已经到来。
稍微啰嗦几句。我做自然语言20多年,原来的自然语言处理有14种任务,我能够把动词找出来、名词找出来、句子分析清楚。即使分析清楚,你知道这是形容词,这是动词,这是名词——那这个名词是包香烟?还是你的舅舅?还是一个坟墓?还是个电影?No idea(不知道)。你需要的是知识。自然语言处理没有知识永远没用。
The only way to make natural language work is you have knowledge(让自然语言处理有效的唯一路径是你有知识)。正好Transformer把这么多知识压缩在一起了,这是它的最大突破。
04
未来是一个模型无处不在的时代
OpenAI未来2-3年要做的——模型更稀疏一点,现在它对带宽要求实在太高,要把attention window拉长一点,或者是recursion causality推理的功能,包括brainstorming等一些工作要做。当然有一些grounding的东西,包括亚符号、子概念的都可以做。更多的模态,更多的token空间,更多的模型稳定性,更多的潜在空间(例如Latent Space对齐),更多的计算,更多的基础架构工具。2-3年基本排满。也就是说,我们大概知道需要什么去把这个引擎继续做大。
不过这个飞轮启动,主要是资本大量进来。美国2023年1月到3月,挡也挡不住,钱全进去了,每个月都在比上个月增长。中国基本也一样,商业模式、盈利模式有初步规模,基础设施、平台应用、生态在加速开发,初创公司、大型企业都在进入。
当然社会的安全、监管,一大堆问题——现在这些是OpenAI最头痛的——Sam在美国花大量精力让社会认可这个技术。现在OpenAI核心做的是,把推进速度变慢,每推进新版本,都有足够时间让用户给他们足够反馈,找到潜在风险点,有足够时间弥补。但加在一起,增长飞轮的雏形基本上起来了。
有了飞轮,我认为发展路径核心是模型的可延伸性和未来模型的生态。是一个模型无处不在的时代。
未来的模型世界会怎么发展?首先是将有更多大模型会出来。更多更完整的模态和更完整的世界知识在这里。你有大量的知识、更多的模态,学习能力、泛化能力和泛化机制一定会加强。
此外,会有更多的对齐工作要做。OpenAI目前会关注什么呢?今天对齐基本上是做到,有一部分人能接受但你也得罪很多人,很多人每天骂GPT。他们想要做到是足够宽的一个对齐,希望有个像美国宪章这样一个结果,虽然ChatGPT不是大家都能够认可,但它足够平稳、综合,大部分人能接受,这是对齐工程。自然语言也好,代码也好,数学公式也好,表单也好,有大量对齐工作要做。
还有更多的模态对齐。这里先讲human scale的模态,它主要是对人的描述,以人的语言为主,它的模态目前是语言和图形,以后有更多的模态会接入。这是大模型层面。
在大模型之上建立的模型更多了。我判断主要是有两类模型和他们的组合。第一是事情的模型,人类每一类需求都有领域/工作模型,其中有结构模型、流程模型、需求模型和任务模型,尤其是记忆和先验。
第二,人的模型,包括认知/任务模型,它是个体的,其中有专业模型,有认知模型、运动模型和人的记忆先验。人基本是这几类模型的组合,律师也好,医生也好,大量领域会有大量模型往前走。
人的模型和学的模型有本质区别,这是我过去1-2个月个人收获较多的。
首先,人一直在建立模型。人的模型好处是泛化的时候更深、更专业,基本是用符号(例如数学公式)或结构(例如画流程图)。它具体用,说实话都不好用。人的模型要么像物理公式解决很宏观的问题,要么解决很微观的问题。我们日常生活的问题,物理一点用都没有——没法告诉我这个树的叶子的形状,狗的猫的颜色为什么是这样子?没有任何模型可以解这个。很大问题是它的模型是静态的,不会场景变化。
今天有很多模型,比方说数字孪生,很难用。因为物理世界一直在变,这个模型僵硬、不变,就用不起来。尤其是用知识图谱建的模型,我做了几十年,超级难算,函数结构差得一塌糊涂。所以人的模型有好处,专业性强,但有很大缺点。
学出来的模型,首先,它本质是场景化的,因为它的token是场景化的。其次,它适应性很强,环境变了,token也变了,模型自然会随着环境变;第三,它的泛化拓展性有大量理论工作要做,但是目前子概念空间的泛化,看来是很有潜在发展空间的这样一种模型的特性。它好用,因为它可以对齐人的使用倾向或人的自然语言、表格等等。它的计算性内在是过程性的。这里有大的问题,就是人表达知识倾向运用结构,但真正能解决问题的是过程,人不适合用过程来表达。
ChatGPT代表的模型跟人的模型相辅相成,长期可以融在一起。我们看到的未来是更多模型的生态,新的领域、新的专业、新的结构、新的场景、新的适应能力,形成闭环,不断加强认知和推理能力。当然,最终还是要所谓叫grounding,跟感知要ground,和接入行动的能力,形成真正的智能。
某种意义上20-30年后,这个模型世界跟生物世界有很多类似的地方。大模型我觉得像基因,有不同的种类,然后进化。我们目前能看到未来核心技术模型世界,它是用这个方法来向前驱动。
我们基本对这个时代的范式有了结构性的理解。那么接下来,我们如何拥抱这个时代
05
每周都有“HOLY SHIT” moment
对每个人、每个行业都有结构性影响
我个人过去10个月,每天看东西是挺多的,但最近实在受不了。就真的是跟不上。发展速度非常非常快。最近我们开始发行“大模型日报”,是我实在不行了,论文实在是跟不上,代码实在是跟不上——just too much(太多了)——基本上,每周都会有一两个“HOLY SHIT” moment。
Holy shit!You can do this now。世界在哗哗哗地变。我曾经说1995-1996年有这种感觉,但这个比1995-1996年还要强。为什么?模型的成本从边际转向固定,知识创造就是模型和知识的获取,它结构性做演变了。
生产资本从两个层次全面提高。第一,所有动脑筋的工作,可以降低成本、提升产能。我们目前有一个基本假设,码农成本会降低,但对码农的需求会大量增加,码农不用担心。因为对软件的需求会大量增加,就是这个东西便宜了,都买嘛。软件永远可以解决更多问题,但有些行业未必。这是生产资本的广泛提高。
第二,生产资本深层提升。有一些行业的生产资本本质是模型驱动,比如医疗就是一个模型行业,一个好医生是一个好模型,一个好护士是一种好模型。医疗这种产业,本质是强模型驱动。现在模型提高了,科学也随之提高。在游戏核心产业,我们的产能将本质性、深度提高。产业的发展速度会加快,因为科学的发展速度加快了,开发的速度加快了,每个行业的心跳都会加快。因此,我们认为下个拐点会加速。用大模型做机器人、自动化、自动驾驶,挡也挡不住。
它对每个人都将产生深远和系统性影响。我们的假设是每个人很快将有副驾驶员,不光是1个,可能5个、6个。有些副驾驶员足够强,变成正驾驶员,他自动可以去帮你做事。更长期,我们每个人都有一个驾驶员团队服务。未来的人类组织是真人,加上他的副驾驶员和真驾驶员一起协同。
毫无疑问,每个行业也会有结构性影响,会系统性重组。这里有一个简单公式。今天动脑筋的人一天平均工资多少小时?减掉ChatGPT现在大概平均是15美元/小时,再过3年可能不到1美元,再过5年可能几十美分。然后就乘一下有多少数量。降本或者增效,让码农能变成super码农,医生变成super医生。
大家可以按这个公式算一算。如果你是华尔街的对冲基金,你可以做空一大堆行业。
举个简单例子,律师在美国平均1500美元/小时,我在网上已经看到每天有这种信息——如果你想离婚,不要找离婚律师,ChatGPT离婚很便宜啊!(全场笑)
开发人员、设计师、码农、研究人员都一样,有些是更多需求,有些是成本下降。尤其是核心产业,科学、教育、医疗,这是OpenAI长期最关注的3个行业,也是整个社会最根本的。
尤其是医疗。在中国,需求远远大于供给。而且,中国是大政府驱动的市场经济,政府可以扮演更大角色,因为固定成本政府可以承担。
最为重要的是教育。如果你是大学,你第一担心的是,考试怎么考?没法考了。他一问ChatGPT,什么都知道。更重要的是,以后怎么定义是好的大学生呢?假定说有个大学生什么都不懂,物理也不懂、化学也不懂,但他懂怎么问ChatGPT,他算不算一个好的大学生?机会与挑战并存。
总结一下,整个这个时代在高速地进行,速度越来越快。它是结构上决定的。势不可挡。
06
大模型的淘金时代
对机会点进行结构性拆解
现在,我给大家一个结构化思维框架。某种意义上你可以对号入座,知道我在这里,我怎么思考今天的机会点。
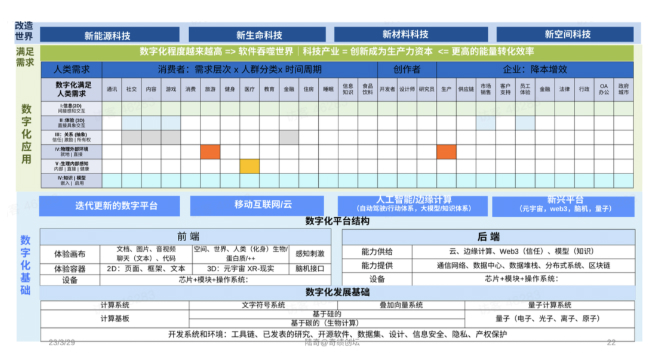
这张图是整个人类技术驱动的创业创新,所有事情的机会都在这张图上。
首先,底层是数字化的技术,因为数字化是人的延伸。数字化的基础里有平台,有发展基础,包括开源的代码、开源的设计、开源的数据;平台有前端、后端等。这里有大量机会。
第二,波是用数字化的能力去解决人的需求。我们把数字化应用完整放在这张表上。
1)C端,是把所有的人分成人群,每种人群24小时,他花时间干什么?有通讯、社交、内容、游戏消费、旅游、健身……C端有一类特殊的人,这类人是改变世界的,是码农、设计师、研究员。他们创造未来。微软这么大的公司,是基于一个简单理念:微软我们就是要写更多软件、帮别人写更多软件,因为写软件是未来。
2)B端,企业需求也一样,降本增效。它要生产,有供应链、销售、客服……有了这些需求之后,数字化看得见的体验结构有6种:给你信息的,二维就够;给你三维交互体验,在游戏、元宇宙;人和人之间抽象的关系,包括信任关系、Web 3;人在物理世界环中自动驾驶、机器人等;人的内在的用碳机植入到里面,今天是脑机接口,以后有更多,以后是可以用硅基;最后是给你模型。
最后,人类是挺奇怪的物种,不光要满足这些需求,还要改变世界,我们在满足世界时,也要获得更多能源,所以需要有能源科技;需要转化能源,用生命科学的形式,biological process转化能源或者使用mechanical process,材料结构来转化能源,或者是新的空间。这是第三波。
所以创业公司基本上有三类:数字化基础,用数字化去解决人的需求,去改变物理世界。有了这个大的框架,我们可以系统性地来看对号入座:我在哪个位置?如果我在这个位置,需要关注哪些点?
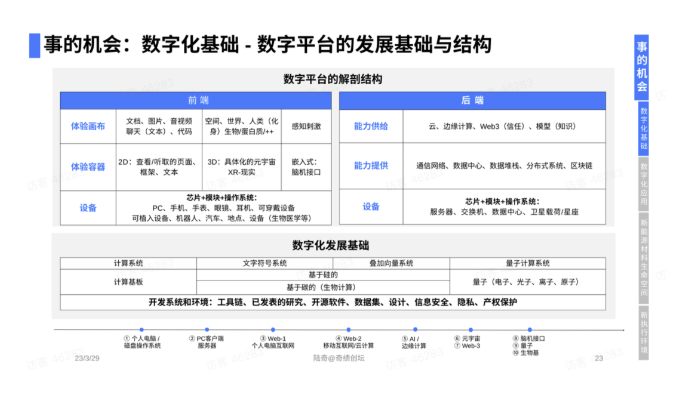
首先讲数字化基础,它有一个稳定结构,不管再怎么发展,结构永远是这样。过去30多年,大部分系统或多或少我都碰过,这个结构确实相当稳定。
核心是前端和后端——前端是完整可延伸的体验,后端是完整可延伸的能力,有设备端,比方说电脑、手机、眼镜、汽车等等,设备端里面是芯片、模组加上操作系统。万亿美元的公司都在这一层。
其次是体验的容器,二维的容器,三维的容器,内在嵌入的容器。
容器之上,写代码都知道画布,画布可以是文档,可以是聊天,可以是代码,可以是空间,可以是世界,可以是数字人,也可以是碳基里的蛋白质等等。这是前端。
后端也一样,底层式设备,服务器、交换机、数据中心等等,也是芯片、模组、操作系统。
中间这一层非常重要,网络数据堆栈,分布式系统,区块链等等。
最上面是云,是能力的供给。能力供给像自然水源,打开就是算力,有存储和通讯能力。今天的模型时代,打开就是模型。
下面是数字化基础。符号计算,或者所谓的深度学习,叠加向量的浮点计算,硅基的,碳基的。
如果你是这里的创业者,机会点在哪里?
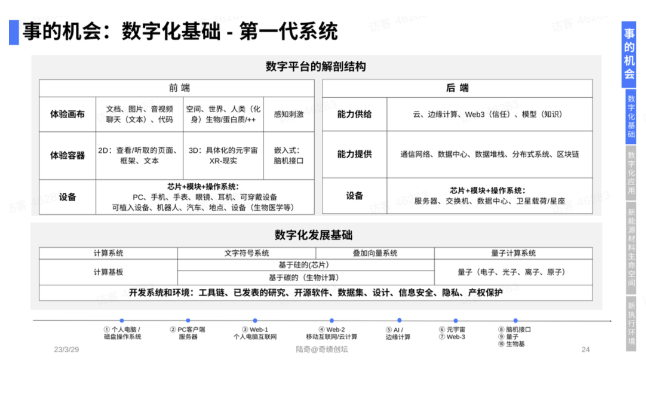
① 首先搬运信息,这个时代还有很多可以做。
② 如果你是做模型的,我现在判断什么都要重做一遍。大模型为先。很多设备也要重做,你要支持大模型,容器要重做,这些都有机会。云、中间的基础设施、底层的硬件,包括数字化发展核心的基础,尤其是开源的体系,这里是真正意义上是有大量机会。
③ 第三代系统,即已经开始做机器人、自动化、自主系统。孙正义今天all in。这个也能用大模型做。马斯克也看到这种机会。都是在第三代下一个拐点,创业公司完全可以把握的机会。
④ 同时并行的,我把它称作“第三代++系统”,是碳基的生物计算,这一类公司有大量的量子计算,有很多机会。元宇宙和Web 3今天点冷,但从历史长河角度来讲,只是时间问题,因为这些技术都能真正意义上带来未来的人类价值。
所以如果是这个创业项目,基础层机会就在这里。这是最好的生意。为什么?这个时代跟淘金时代很像。如果你那个时候去加州淘金,一大堆人会死掉,但是卖勺子的人、卖铲子的人永远可以赚钱。所谓的shove and pick business。
大模型是平台型机会。按照我们几天的判断,以模型为先的平台,将比以信息为先的平台体量更大。平台有以下几个特征:
① 它是开箱即用;
② 要有一个足够简单和好的商业模式,平台是开发者可以活在上面,可以赚足够的钱、养活自己,不然不叫平台;
③ 他有自己杀手级应用。ChatGPT本身是个杀手应用,今天平台公司就是你在苹果生态上,你做得再好,只要做大苹果就把你没收了,因为它要用你底层的东西,所以你是平台。平台一般都有它的锚点,有很强的支撑点,长期OpenAI设备机会有很多——有可能这是历史上第一个10万亿美元的公司。
这是一场激烈的竞争平台之战,未来一个体量很大的公司。在这个领域竞争是无比激烈。The price is too big(代价实在太大),错过太可惜。再怎么也得试一试。
今天的模型鲁棒性、脆弱性,还是问题。用这个模型,你一定要一开始稍微窄一点,限制要严一点,这样的话体验是稳定的,等到模型能力越来越强再把它放宽,找到适当的场景,循序渐进。质量和宽度之间的平衡很重要。另外发展路径上,你要考虑今天产品要不要在这个上基础上改,重启炉灶,还是齐头并进。把这个团队给改了、重做,还到外面去买公司?
创新,尤其是创业公司落地,它永远是技术推动和需求拉动的组合。在落地的过程中,对需求理解的把控,掌握和满足需求的方法是一切当中最重要。长期一定是技术驱动为主,但在落地的时候对需求的拆解、分析、梳理,把控好需求,是一切的一切。
有一个机密大家今天都知道了——OpenAI是用GPT-4做GPT-5,每个码农都是放大能力的码农。它规模效应不一样,马太效应不一样,从此壁垒和竞争格局不一样,知识产权结果不一样,国际化的格局也不一样。中国显然有机会。
07
我对创业者有几点建议
创业公司的内在结构是人和事的组合。人,一开始是创始人/创始团队;他有初心,内在驱动力、外在驱动力;他能独立思考,判断未来;他能行动导向,解决问题;他能需求导向,找到价值;最终通过沟通获得资源。接下来是产品市场匹配,这部分就是研发技术、研发产品、交付产品。商业模式是收到钱、更多增长、触达更多客户、融更多钱、一直触达到未来的价值。组织上,通过系统建设,开拓面向未来的人才、组织结构和文化价值观等等。这一切就是一家公司的总和。
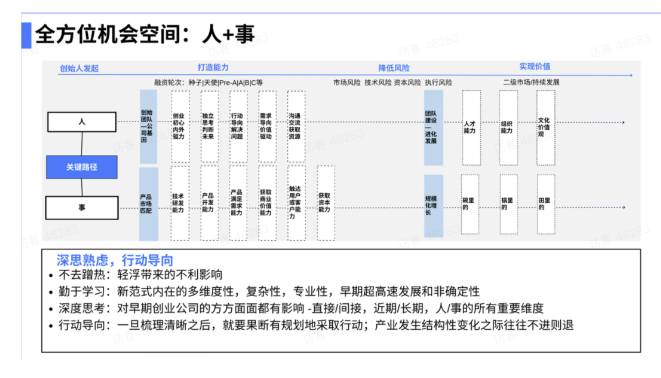
我们对每位同学的建议是,不要轻举妄动,首先要思考。
① 不要浮夸,不能蹭热。我个人最反对蹭热,你要做大模型,想好到底做什么,大模型真正是怎么回事,跟你的创业方向在哪个或哪几个维度有本质关系。蹭热是最不好的行为,会浪费机会。
② 在这个阶段要勤于学习。新范式有多个维度,有蛮大复杂性,该看到的论文要看,尤其现在发展实在太快,非确定性很大。我的判断都有一定灰度,不能说看得很清楚,但大致是看到是这样的结果。学习花时间,我强烈推荐。
③ 想清楚之后要行动导向,要果断、有规划地采取行动。如果这一次变革对你所在的产业带来结构性影响,不进则退。你不往前走没退路的,今天的位置守不住。如果你所在的产业被直接影响到,你只能采取行动。
接下来我想讲几个维度——每个公司是一组能力的组合。
① 产品开发能力方面,如果你的公司以软件为主,毫无疑问一定对你有影响,长期影响大得不得了。尤其是如果你是做C端,用户体验的设计一定有影响,你今天就要认真考虑未来怎么办。
② 如果你的公司是自己研发技术,短期有局部和间接影响,它可以帮助你思考技术的设计。长期核心技术的研发也会受影响。今天芯片的设计是大量的工具,以后大模型一定会影响芯片研发。类似的,蛋白质是蛋白质结构设计。不管你做什么,未来的技术它都影响。短期不直接影响,长期可能有重大影响。
③ 满足需求能力,满足需求基本就要触达用户,供应链或运维一定受影响。软件的运维可以用GPT帮你做,硬件的供应链未必。长期来看有变革机会,因为上下游结构会变。你要判断你在这个产业的结构会不会变。
④ 商业价值的探索、触达用户、融资,这一切它可以帮你思考、迭代。
最后是关于人才和组织。
① 首先讲创始人。今天创始人技术能力强,好像很牛、很重要,未来真的不重要。技术ChatGPT以后都能帮你做。你作为创始人,越来越重要、越来越值钱的是愿力和心力。愿力是对于未来的独到的判断和信念,坚持、有强的韧劲。这是未来的创始人越来越重要的核心素养。
② 对初创团队,工具能帮助探索方向,加速想法的迭代、产品的迭代,甚至资源获取。
③ 对未来人才的培养,一方面学习工具,思考和探索机会,长期适当时候培养自己的prompt engineer(提示工程师)。
④ 最后讲到组织文化建设,要更深入思考,及早做准备,把握时代的机会。尤其是考虑有很多职能已经有副驾驶员,写代码也好,做设计也好,这之间怎么协同?
我们面临这样一个时代的机会。它既是机会,也是挑战。我们建议你就这个机会做全方位思考。



