












5.1.1 视图的概念和特点
- 视图是一种数据库对象,是一个从一张表、多张表或视图中导出的虚表。视图的结构和数据是对数据表进行查询的结果
- 视图仅存放视图的定义,不存放视图所对应的数据
- 如果基表中的数据发生变化,则从视图中查询出的数据也随之改变
5.1.2 视图的优点
- 关注点聚焦:用户仅关心其感兴趣的某些特定数据和其所负责的特定任务,而不关心其他无关的数据和任务
- 简化操作:无须重新编写复杂的查询语句,只要执行一条简单的查询视图语句即可
- 定制数据:能够实现不同的用户以不同的方式看到数据集
- 在合并分割数据时保持数据表原有结构关系:使用视图就可以保持数据表原有的结构关系,使得原有的应用程序仍可以通过视图来访问表数据
- 细粒化的安全机制:视图提供了一种细粒化的安全机制,通过合理创建视图,可以把权限限定到行列级别
5.1.3 使用企业管理器创建视图
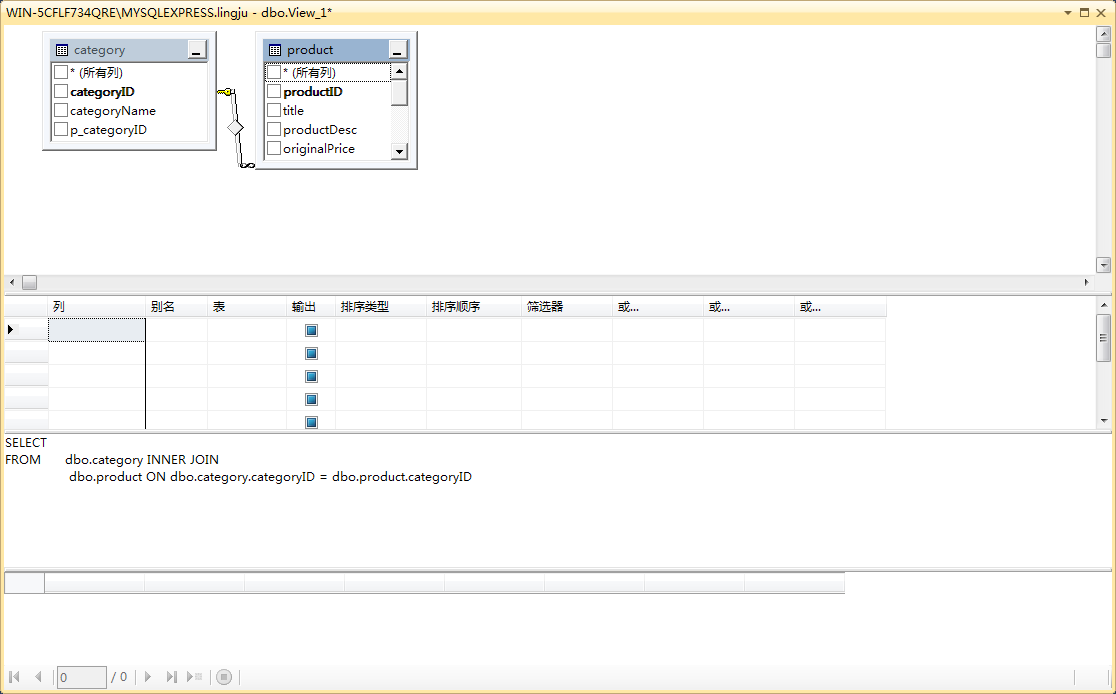
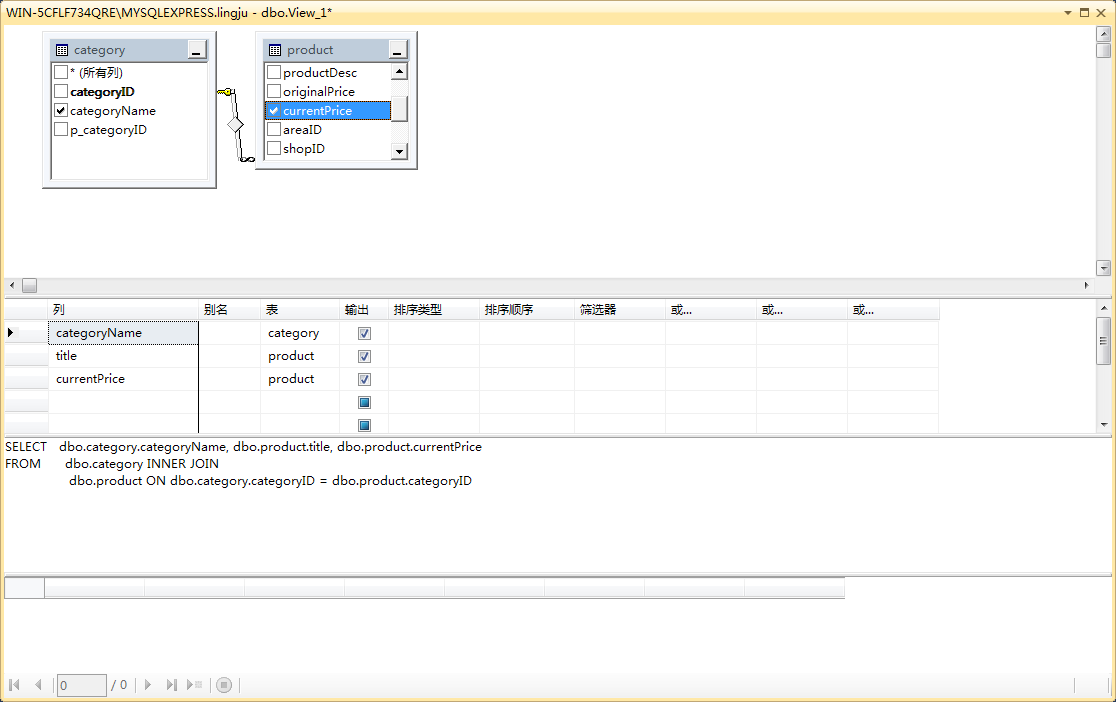
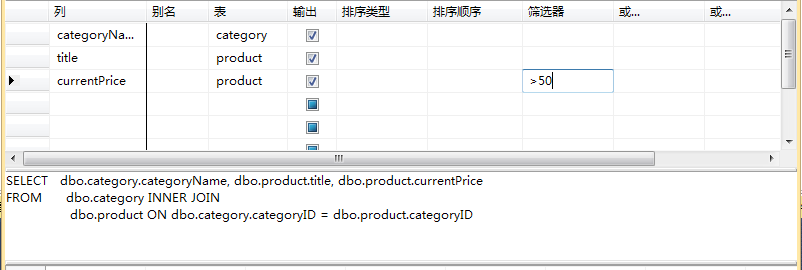
使用企业管理器(SQL Server Management Studio,SSMS)管理平台,创建团购价高于 50 元的商品信息视图,用于查看商品标题、商品类型名和团购价


5.1.4 使用 T-SQL 创建视图
利用 create view 语句可以创建视图
语法:create view [ schema_name . ] view_name [ (column [ , … n ] ) ] as select_statement
创建视图的 T-SQL 语句
示例:create view v_product_category_area_shop as select p.title 商品标题 , c.categoryName 商品类型名 , p.currentPrice 团购价 ,a.areaName 地区名 ,s.shopName 商店名 from product p,category c,area a,shop s where p.categoryID=c.categoryID and p.areaID=a.areaID AND p.shopID=s.shopID and p.currentPrice>50
select * from v_product_category_area_shop

5.1.5 使用视图创建复杂查询
创建一个用于生成每个订单金额的视图,并利用该视图来更新订单表中相应订单的金额
示例:create view v_ordersAmount as select od.ordersID, sum(p.currentPrice*od.quantity) calamount from orders o, ordersdetail od,product p where o.ordersID=od.ordersID and p.productID=od.productID group by od.ordersID
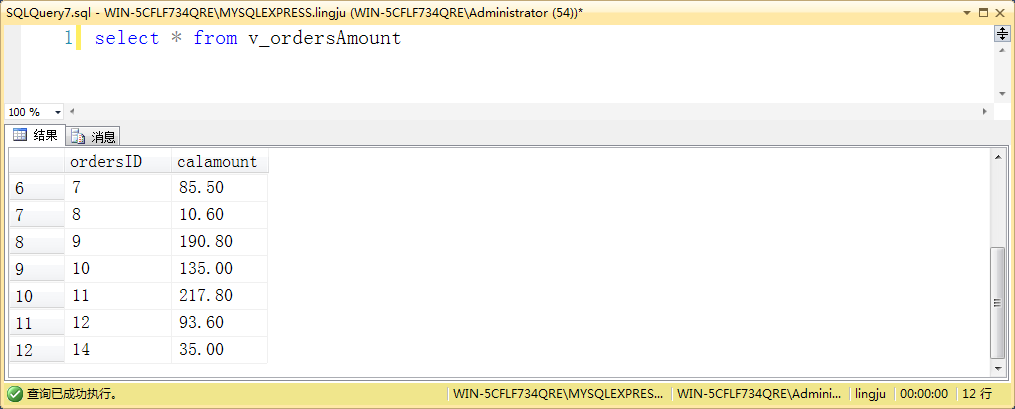
利用视图 v_ordersAmount 中的 calAmount 列值更新订单表中的 amount 列值
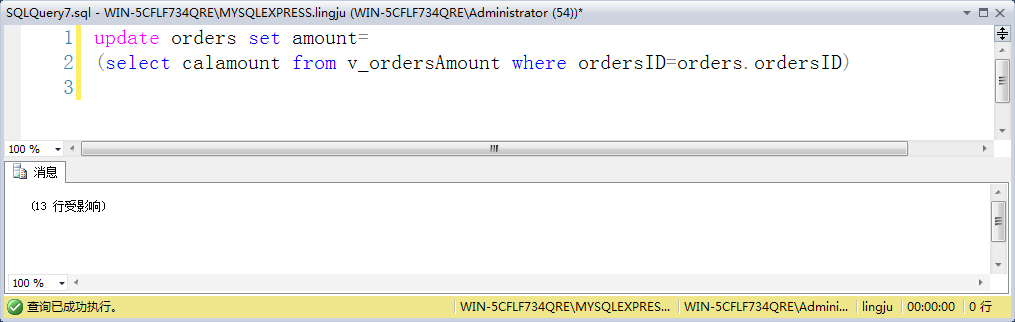
示例:update orders set amount= (select calamount from v_ordersAmount where ordersID=orders.ordersID)
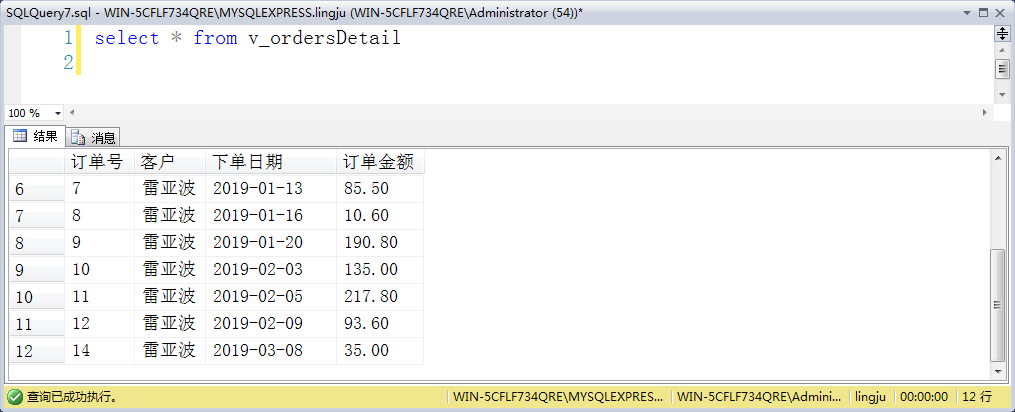
检索所有订单的客户名、下单日期和订单金额,通过查询该视图就可以快速获得每个订单的详细信息
示例:create view v_ordersDetail as select o.ordersID 订单号 , c.customerName 客户 , o.ordersDate 下单日期 , sum(p.currentprice*od.quantity) 订单金额 from orders o, ordersdetail od, product p, customer c where o.ordersID=od.ordersID and od.productID=p.productID and o.customerID=c.customerID group by o.ordersID,c.customerName, o.ordersDate
5.2流程控制语句
5.2.1 索引概述
在数据库应用系统中,对数据查询的处理速度已成为衡量应用系统成败的标准。而采用索引来加快数据处理速度是最普遍的优化方法
索引的根本目的在于快速检索,建立该索引后,数据库系统会建立一个新的表,该表只有一列,该列的值即为指向所有的 product中 name 的指针,实际上,后台还会建立一个相应的数据结构,如 B+Tree,为快速检索提供基础

索引的作用
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面更有意义
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能
索引的缺点
- 因为创建索引所需的工作空间约为数据库表的 1.2 倍,所以带索引的表在数据库中会占据更多的空间
- 为维护索引,在对数据进行插入、更新和删除操作时会耗费系统时间
- 在建立索引时,由于需要复制数据,同样会耗费系统的时间和空间
索引的使用场合
- 在经常需要搜索的列上,可以加快搜索的速度
- 在作为主键的列上
- 在经常用在连接的列上,这些列主要是一些外键,在这些列上建立索引可以加快连接的速度
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的
- 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,节省排序查询的时间
- 在使用 where 子句的列上创建索引,加快条件的判断速度
视图是一种数据库对象,是一个从一张表、多张表或视图中导出的虚表。视图的结构和数据是对数据表进行查询的结果
- 对于那些在查询中很少使用或参考的列不应该创建索引
- 对于那些只有很少数据值的列而言,同样不应该增加索引
- 对于那些定义为 text、image 和 bit 数据类型的列不应该增加索引
- 当修改性能远大于检索性能时,不应该创建索引
5.2.2 索引分类
- 以存储结构来区别,有“聚集索引”(Clustered Index,也称聚类索引、簇集索引)和“非聚集索引”(NonClusteredIndex,也称非聚类索引、非簇集索引)之分
- 以数据的唯一性来区别,有“唯一索引”(Unique Index)和“非唯一索引”(NonUnique Index)之分;以索引列的个数来区分,则有“单列索引”与“多列索引”之分
- 聚集索引将数据行的值在表内排序,并存储对应的数据记录,使数据表物理顺序与索引顺序相一致
- 当以某字段作为关键字建立聚集索引时,表中数据以该字段作为排序依据。因此,一个表仅能建立一个聚集索引,主键默认为聚集索引
- 非聚集索引也称为普通索引,它是一种完全独立于数据行的文件结构。数据存储在一个地方,索引存储在另一个地方。非聚集索引中的数据排列顺序并非表中数据的排列顺序
聚集索引与非聚集索引的比较
- 聚集索引相比非聚集索引,在插入数据时速度要慢,因为需要在物理存储的排序上花费时间,但聚集索引在查询数据时速度要比非聚集索引更快。
- 聚集索引所需空间小于非聚集索引,如果硬盘和内存空间有限,则应限制非聚集索引的使用
|
索引分类 |
插入数据速度 |
查询数据速度 |
索引的数量 |
所需空间 |
|
聚集索引 |
慢 |
快 |
一表一个 |
小 |
|
非聚集索引 |
快 |
慢 |
一表可以多个 |
大 |
唯一索引, SQL Server 自动在唯一约束列上创建唯一索引,一般情况下,唯一索引默认为聚集索引
5.2.3 创建索引
- 自动创建索引,SQL Server 在创建表中的其他对象时,可以附带创建新索引。通常情况下,SQL Server 在创建 unique 约束或primary key 约束时,系统会自动在这些约束列上创建聚集索引
- 用户创建索引,SQL Server 除了能自动生成索引,还可以根据实际需要,使用 SQL Server 集成开发平台,如 SSMS,或利用SQL 语句“create index 索引名”命令直接创建索引
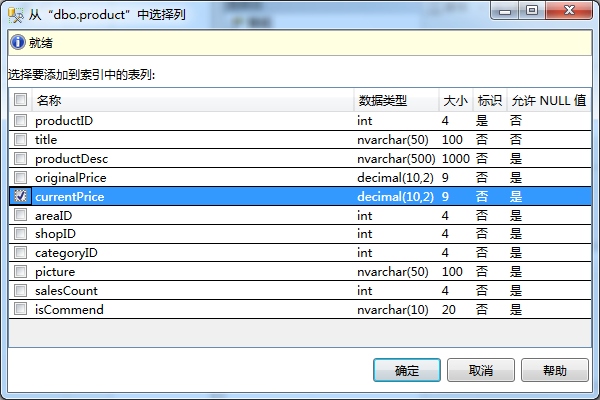
使用SSMS创建索引


使用 T-SQL 命令创建索引的语法如下:
语法:create [unique] [clustered|nonclustered] index index_name on table_name (column_name…)
创建索引的 T-SQL 语句
示例:create index idx_price on product(currentPrice) create unique index idx_unique_title on product(title)
5.2.4 使用 T-SQL 命令删除索引
使用drop命令和alter命令删除索引的命令
语法:drop index index_name on table_name
或 alter table table_name drop index index_name
使用 drop 命令和 alter 命令删除 product 表的 idx_price 索引
示例:drop index idx_price on product alter table product drop index idx_price
5.2.5 在多个字段上创建组合索引(多列索引)
索引可以是单列索引,也可以是多列索引,检索出团购价小于 50 元的火锅信息
示例:select * from product where currentPrice<50 and title like '% 火锅 %';
create index idx_price_title on product(currentPrice,title) 在 currentPrice 列和 title 列分别创建索引
5.3数据库事务
5.3.1 事务概述
事务是一个由用户所定义的完整的工作单元,一个事务内的所有语句作为一个整体来执行。即要么全部执行,要么全部不执行
当遇到错误时,可以回滚事务,取消事务内所做的所有改变,从而保证数据库中数据的一致性和可恢复性
5.3.2 事务特性
数据库事务有 4 大特性,简称 ACID
- 原子性(atomic、atomicity)
- 一致性(consistent、consistency)
- 隔离性(isolation)
- 持久性(duration、durability)
5.3.3 事务的分类
显式事务,显式事务是指需要由用户显式的定义事务的开始和结束,显式事务由用户定义
- begin transaction:标识一个事务的开始,即启动事务
- commit transaction:提交事务。标识一个事务的结束,事务内所修改的数据被永久保存到数据库中
- rollback transaction:回滚事务。标识一个事务的结束,表明在事务执行过程中遇到错误,事务内所修改的数据被回滚到事务执行前的状态
隐式事务,隐式事务是指当前事务提交或回滚后,SQL Server 自动开始下一个事务
隐式事务不需要使用 begin transaction 语句启动事务,仅需要用户使用 commit transaction 或 rollback transaction 语句提交或回滚事务。执行 set implicit_transactions on 语句可使 SQL Server 进入隐式事务模式
自动提交事务,自动提交事务是 SQL Server 默认的事务模式,其将每个 T-SQL 语句都视为一个事务,如果成功执行,则自动提交;如果出现错误,则自动回滚
5.4触发器
5.4.1 触发器概述
- 触发器(trigger)是 SQL Server 提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发
- 执行 insert、delete 和 update 时就会激活它执行。触发器经常用于加强数据的完整性约束和业务规则等
- 触发器主要用于监视某个表的 insert、update 以及 delete 等数据维护操作,这些维护操作可以分别激活该表的insert、update 或者 delete 类型的触发程序运行,从而实现数据的自动维护
- 触发器可以实现的功能包括:使用触发器实现检查约束、维护冗余数据,维护外键列数据等
触发器的优点
- 触发器是自动的。当对表中的数据做了任何修改之后立即被激活
- 触发器可以通过数据库中的相关表进行层叠修改
- 触发器可以强制限制,这些限制比用 check 约束所定义的更复杂。与 check 约束不同的是,触发器可以引用其他表中的列
触发器的主要作用
- 强制数据库间的引用完整性
- 级联修改数据库中所有相关的表,自动触发其他与之相关的操作
- 跟踪变化,撤销或回滚违法操作,防止非法修改数据
- 返回自定义的错误消息,约束无法返回信息,而触发器可以
- 触发器可以调用更多的存储过程
SQL Server 创建触发器的语法如下:
语法:create trigger trigger_name on table_name for | after | instead of delete | insert | update as sql_statement
inserted 表和 deleted 表。这两个表由系统来维护,它们存在于内存中而不是在数据库中。这两个表的结构总是与被该触发器作用的表的结构相同。触发器执行完成后,与该触发器相关的这两个表也被删除
inserted 表和 deleted 表的作用
- inserted 表存放在由于执行 insert 或 update 语句而要向表中插入的所有行
- deleted 表存放在由于执行 delete 或 update 语句而要从表中删除的所有行
5.4.2 instead of 触发器和 after 触发器
- Instead of 触发器和 after 触发器。这两种触发器的差别在于它们被激活时触发器代码的逻辑功能的不同
- Inserted of 触发器的特点:instead of触发器用来代替通常的触发动作,即当对表进行 insert、update或delete操作时,系统不是直接对表执行这些操作,而是把操作内容交给触发器,让触发器检查所进行的操作是否正确。如正确才进行相应的操作
- after 触发器的特点:after 触发器定义了对表执行 insert、update 或 delete 语句操作之后再执行的操作。比如对某个表中的数据进行了更新操作后,要求立即对相关的表进行指定的操作,这时就可以采用 after 触发器。after 触发器只能在表上指定,且动作晚于约束处理
5.4.3 instead of 触发器实现数据新增
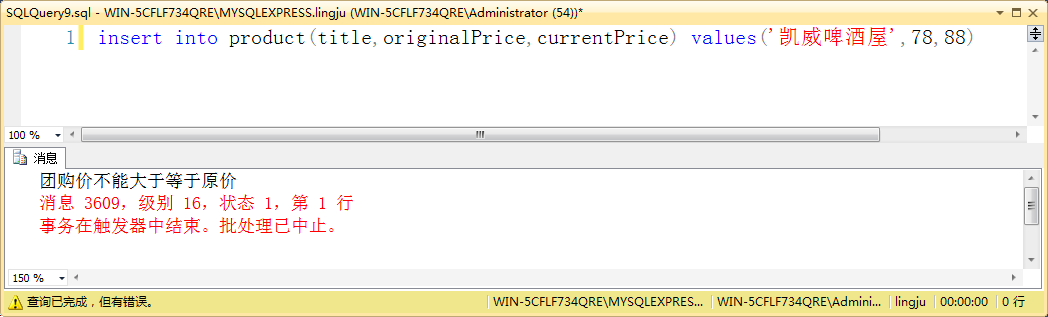
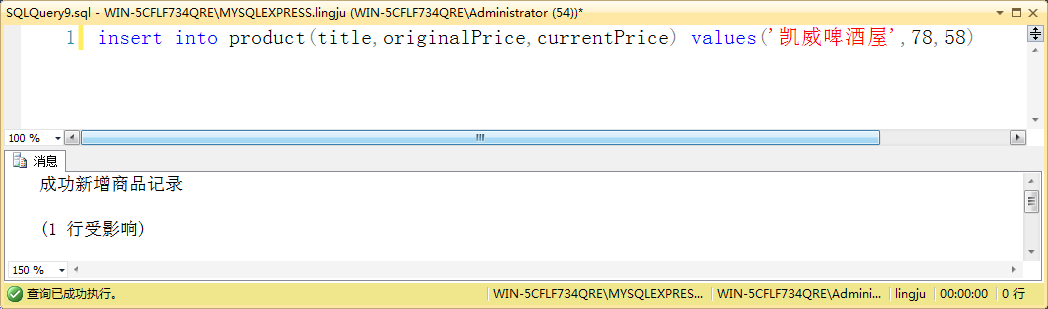
新增商品数据时,使用 instead of 触发器用于确保新增产品的团购价低于原价。
示例:use lingju go if exists(select * from sysobjects where name='trig_insertProduct') drop trigger trig_insertProduct go create trigger trig_insertProduct on product instead of insert as declare @title nvarchar(50) declare @originalPrice decimal(10,2), @currentPrice decimal(10,2) select @title=title,@originalPrice=originalPrice,@currentPrice=currentPrice from inserted if @currentPrice>=@originalPrice begin print ' 团购价不能大于等于原价 ' end else begin print ' 成功新增商品记录 ' insert into product(title,originalPrice,currentPrice values(@title,@originalPrice,@currentPrice) end
5.4.4 after 触发器实现数据新增
新增商品数据时,使用after触发器确保新增产品的团购价低于原价
示例:use lingju go if exists(select * from sysobjects where name='trig_insertProduct') drop trigger trig_insertProduct go create trigger trig_insertProduct on product after insert as declare @originalPrice decimal(10,2), @currentPrice decimal(10,2) select @originalPrice=originalPrice, @currentPrice=currentPrice from inserted if @currentPrice>=@originalPrice begin print ' 团购价不能大于等于原价 ' rollback transaction end else begin print ' 成功新增商品记录 ' end
总结 :
- 视图是一种数据库对象,是一个从一张表、多张表或视图中导出的虚表。视图的结构和数据是对数据表进行查询的结果
- 触发器是 SQL Server 提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发
- 事务必须是一个原子工作单元。对于其数据修改,要么全都执行,要么全都不执行
- begin transaction:标识一个事务的开始,即启动事务
- commit transaction:提交事务
- rollback transaction:回滚事务



