










ChatGPT 代替程序员,是我们想多了?
在 OpenAI 发布 GPT-4 之后,一场有关「AI 取代人类劳动力」的讨论正变得越来越激烈。该模型的强大能力及其可能带来的潜在社会影响引发了很多人的担忧,马斯克、Bengio 等人甚至联名写了一封公开信,呼吁所有 AI 机构暂停训练比 GPT-4 更强的 AI 模型,为期至少 6 个月。
但另一方面,对于 GPT-4 能力的质疑也是此起彼伏。前几天,图灵奖得主 Yann LeCun 在一场辩论中直接指出,GPT 家族所采用的自回归路线存在天然的缺陷,继续往前走是没有前途的。
与此同时,一些研究者、从业者也表示,GPT-4 可能并没有 OpenAI 所展示的那么强大,尤其是在编程方面:它可能只是记住了之前的题目,OpenAI 用来测试该模型编程能力的题目可能早就存在于它的训练集中,这违反了机器学习的基本规则。另外,还有人指出,看到 GPT-4 在各种考试中名列前茅就判定 AI 将取代部分职业的想法是不严谨的,毕竟这些考试和人类的实际工作还是有差距的。
近期的一篇博客详细地阐述了上述想法。
问题一:训练数据污染
为了对 GPT-4 的编程能力进行基准测试,OpenAI 使用编程竞赛网站 Codeforces 上的问题对其进行了评估。令人惊讶的是,GPT-4 解决了 10/10 的 2021 年前的问题和 0/10 的近期 easy 类问题。要知道,GPT-4 的训练数据截止日期是 2021 年 9 月。这有力地表明该模型能够从其训练集中记住解决方案 —— 或者至少部分记住它们,这足以让它填补它不记得的东西。
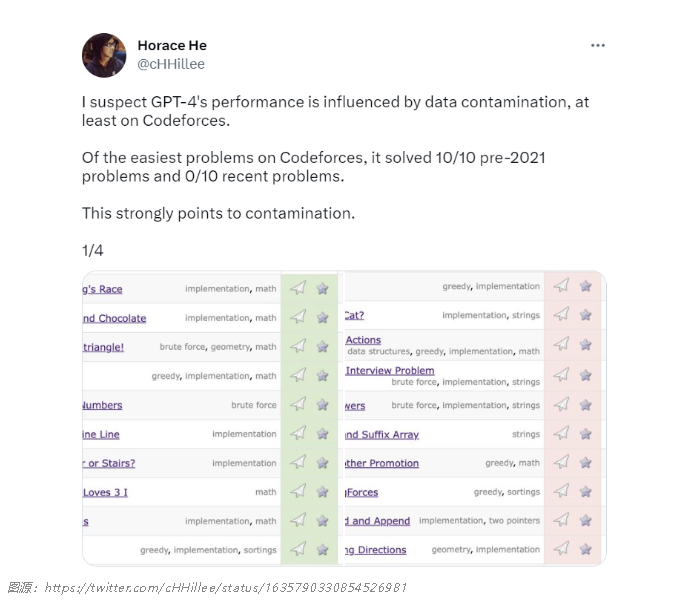
为了进一步证明这一假设,博客作者 Arvind Narayanan 和 Sayash Kapoor 在 2021 年不同时间的 Codeforces 问题上对 GPT-4 进行了测试,发现它可以解决 9 月 5 日之前的简单类别的问题,无法解决 9 月 12 日之后的问题。
作者表示,事实上,他们可以明确地表明 GPT-4 已经记住了训练集中的问题:当把 Codeforces 问题的标题加入 prompt 中时,GPT-4 的回答会包含指向出现该问题的确切比赛的链接(并且轮数几乎是正确的:它差了一个)。注意,当时的 GPT-4 不能上网,所以记忆是唯一的解释。

论文中的 Codeforces 结果并没有受此影响,因为 OpenAI 使用的是最近的问题(果然,GPT-4 表现很差)。对于编程以外的基准,作者不知道有什么干净的方法可以按时间段分开问题,所以他们认为 OpenAI 不太可能避免污染。但出于同样的原因,他们也无法做实验来测试性能在不同日期的变化情况。
不过,他们还是可以寻找一些提示性的迹象。记忆的另一个征兆是:GPT 对问题的措辞高度敏感。Melanie Mitchell 举了一个 MBA 测试题的例子,她改变了这个例子的一些细节,这一改变骗不到人,但却成功欺骗了(运行 GPT-3.5 的)ChatGPT。沿着这个思路做一个更详细的实验会很有价值。
由于 OpenAI 缺乏透明度,作者无法肯定地回答污染问题。但可以肯定的是,OpenAI 检测污染的方法是肤浅和草率的:
我们使用子串匹配来衡量我们的评估数据集和预训练数据之间的交叉污染。评估和训练数据都是通过去除所有的空格和符号来处理的,只保留字符(包括数字)。对于每个评估实例,我们随机选择三个 50 个字符的子串(如果少于 50 个字符,则使用整个实例)。如果三个被抽中的评估子串中的任何一个是被处理过的训练例子的子串,那么就可以识别出一个匹配。这就产生了一个被污染的例子的列表。我们丢弃这些,并重新运行以获得未受污染的分数。
这是一个脆弱的方法。如果一个测试问题出现在训练集中,但名称和数字被改变了,它就不会被发现。不那么脆弱的方法是现成的,比如说嵌入距离。
如果 OpenAI 要使用基于距离的方法,多大程度的相似才是太相似?这个问题没有客观的答案。因此,即使是像选择题标准化测试中的表现这样看似简单的事情,也充满了主观的决定。
但我们可以通过询问 OpenAI 试图用这些考试来衡量什么来明确一些东西。如果目标是预测语言模型在现实世界任务中的表现,那就有一个问题。从某种意义上说,任何两个律师考试或医学考试的问题都比现实世界中专业人士所面临的两个类似任务更相似,因为它们是从这样一个受限的空间中提取的。因此,在训练语料库中加入任何考试问题,都有可能导致对模型在现实世界中的有用性的夸大估计。
从现实世界的有用性角度来阐述这个问题,突出了另一个更深层次的问题(问题二)。
问题二:专业考试不是比较人类和机器人能力的有效方法
记忆是一个光谱。即使一个语言模型在训练集上没有见过某个确切的问题,它也不可避免地看到了非常接近的例子,因为训练语料库的规模太大了。这意味着它可以用更浅显的推理水平来逃避。因此,基准结果并没有给我们提供证据,证明语言模型正在获得人类考生所需要的那种深入的推理技能,而这些考生随后会在现实世界中应用这些技能。
在一些现实世界的任务中,浅层推理可能是足够的,但并不总是如此。世界是不断变化的,所以如果一个机器人被要求分析一项新技术或一个新的司法判决的法律后果,它就没有什么可借鉴的。总之,正如 Emily Bender 所指出的,为人类设计的测试在应用于机器人时缺乏结构效度。

除此之外,专业考试,尤其是律师资格考试,过度强调学科知识,而对现实世界的技能强调不足,而这些技能在标准化的计算机管理方式下更难衡量。换句话说,这些考试不仅强调了错误的东西,而且过度强调了语言模型所擅长的东西。
在 AI 领域,基准被过度地用于比较不同的模型。这些基准因将多维评价压缩成一个单一数字而饱受批评。当它们被用于比较人类和机器人时,得到的结果是错误的信息。不幸的是,OpenAI 在对 GPT-4 的评估中选择大量使用这些类型的测试,而且没有充分尝试解决污染问题。
有更好的方法来评估 AI 模型对职业的影响
人们在工作期间可以上网,但在标准化考试期间却不能上网。因此,如果语言模型的表现能够媲美可以上网的专业人士,这在某种程度上将能更好地检验它们的实际效能。
但这仍然是个错误的问题。与其用独立的基准,我们或许更应该衡量语言模型能在多大程度上完成专业人员必须完成的所有现实任务。例如,在学术界,我们经常会遇到一些我们不熟悉的领域的论文,其中充满了专业术语;如果 ChatGPT 能够以一种更容易理解的方式准确地总结这样的论文,那就很有用了。有些人甚至还测试过这些工具是否能做同行评议。但即使是这个场景,你也很难确保用来测试的题目没有包含在训练集里。
ChatGPT 可以取代专业人员的想法仍然很牵强。在 1950 年的普查中,270 个工作中仅有 1 个被自动化淘汰了,那就是电梯操作员。当下,我们需要评估的是那些利用人工智能工具来帮助自己完成工作的专业人员。两项早期的研究是有希望的:一项是 GitHub 用于编程的 copilot,另一项是 ChatGPT 的写作协助。
在这个阶段,我们更需要定性研究而不是定量研究,因为这些工具太新了,我们甚至不知道该问什么正确的定量问题。例如,微软的 Scott Guthrie 报告了一个醒目的数字:GitHub Copilot 用户检查的代码中有 40% 是人工智能生成的,没有经过修改。但任何程序员都会告诉你,很大一部分代码由模板和其他通常可以复制粘贴的平凡逻辑组成,特别是在企业应用程序中。如果这就是 Copilot 自动化的部分,那么生产力的提高将是微不足道的。
作者表示,明确地说,我们不是说 Copilot 没有用,只是说如果没有对专业人士如何使用人工智能的定性理解,现有的衡量标准将是没有意义的。此外,人工智能辅助编码的主要好处甚至可能不是生产力的提高。
结论
下图总结了这篇文章,并解释了我们为什么要以及如何摆脱 OpenAI 报告的那种度量标准。

GPT-4 确实令人兴奋,它可以通过多种方式解决专业人士的痛点,例如通过自动化,代替我们做简单、低风险但费力的任务。目前,专注于实现这些好处并降低语言模型的许多风险可能是更好的做法。



